Back when I worked for the Nokia TAC support Check Point Security Gateways, I actually ran a Nokia appliance as the headend for my network. One could call it "keeping my skills sharp for my daily work." For a variety of reasons, I discontinued this practice and instead opted for more traditional home routers that I could install DD-WRT on.
When I started working for Check Point, I alternated between either running a DD-WRT router or using a UTM-1 EDGE appliance. When Check Point announced the SG80 (and later the 1100 series appliance), I moved to using those.
And while I probably could continue to use the 1100 series appliance for some time, I finally got my hands on a 2200 Appliance and decided that it should be the headend to my home Internet connection. I wanted to be able to use all the latest Check Point features and get my hands a bit dirtier than I have in a while. What better way to do that than with my family, which is very good at generating lots of real-world, Internet-bound traffic :)
DHCP and DNS Server on the Gateway
Every gateway I've used in the last several years had a DHCP server. In most cases, it also included a DNS server. Gaia does have a built-in DHCP server, and should you use it, should make sure to configure your rulebase to permit the traffic correctly as described in sk98839.
That said, it's not currently possible to make the Gaia DHCP server authoritative for a given subnet without manually hacking the dhcpd.conf file (see sk92436 and sk101525). I did this, which worked.
I still wanted a local DNS server too where I could define local DNS entries for items on my subnet. I could have easily used dnsmasq on one of the many DD-WRT routers I still have on my network as WiFi access points, but I wanted it on the Security Gateway, just like I had it on my 1100, UTM-1 EDGE, and others. I poked around a bit on my Gaia R77.20 installation and discovered that it too had dnsmasq.
I want to be clear: dnsmasq is not formally supported on Gaia. That said, it appears to work quite nicely. The configuration file /etc/dnsmasq.conf is not managed through Gaia and, as far as I know, it should survive upgrades and the like and not be affected by anything you do in Gaia, except maybe enable the DHCP server in Gaia, which obviously do you don't want to do if you're going to use dnsmasq for this.
The dnsmasq in Gaia appears to take most of the common configuration options, so I set about configuring it as described in the dnsmasq documentation. Starting it up is pretty simple: a service dnsmasq start from Expert mode gets it going.
But, of course, that only works until the next reboot. Now I could have hacked /etc/rc.local or something like that, but I know how to make Gaia's configuration system actually start this process for me, monitor it, and restart it if it dies.
[Expert@animal:0]# dbset process:dnsmasq t
[Expert@animal:0]# dbset process:dnsmasq:path /usr/sbin
[Expert@animal:0]# dbset process:dnsmasq:runlevel 3
[Expert@animal:0]# dbset :save
I guess all those years of supporting IPSO paid off :) If you want to turn off dnsmasq in the future, issue the following commands from Expert mode:
[Expert@animal:0]# dbset process:dnsmasq
[Expert@animal:0]# dbset :save
One other thing you might want to do if you're running a local DNS server is have your Security Gateway actually use it. The problem is: dhclient (which obtains settings from a DHCP server) actually overwrites the configuration in Gaia for the DNS domain and the DNS servers to use. You should be able to prevent this by changing the /etc/dhclient.conf configuration file not to use this information.
Specifically, it means changing this line:
request ntp-servers, subnet-mask, host-name, routers, domain-name-servers, domain-name;
to this:
request ntp-servers, subnet-mask, host-name, routers;
To be absolutely clear, Check Point does not support using dnsmasq at all for any purpose on Gaia. While I am using it successfully in R77.20, it could easily be removed in a future version at a future date.
DHCP and the Default Route on the Internet Interface
When I put the 2200 in my network, I noticed that Gaia was not accepting the default route from Comcast's DHCP server. To get my home network oeprational, I manually set the default route to my Internet-facing interface, which seemed to work for a time.
One persistent issue I was having, that I initially was unable to figure out, was that it would take some time in order for sites to load. I wasn't quite sure why, but it was only happening occasionally and not something I could easily track down. I ignored it for a couple of weeks, but last night the problem really came to a head.
I thought Comcast was having a problem. I even went so far as to call Comcast and they said there was some signal problem on their end. The problem still persisted. The only thing "different" was that we had visitors who brought a laptop with him and was playing League of Legends with my son.
I tried a number of things, and couldn't figure out what was going on. I did start seeing some peculiar traffic on my external interface, and decided on a fluke to check my arp table. Rather than the 20-30 entries I'm used to seeing, I was seeing over 700 entries. For IPs on the Internet. That didn't look right. And sure enough, I was seeing arp whois requests for Internet IPs coming from my gateway.
Arping for every IP you access on the Internet is not terribly efficient. Comcast was, understandably, not responding to these ARP requests quickly, though they eventually did. Furthermore, due to the transient nature of ARP entries, they were timing out every minute or so, which meant that as long as I was actively passing traffic, connections to websites worked great. When I stopped and reconnected? It would take forever to connect.
Which brings me back to the original problem I had: getting Gaia to take a default route from a DHCP server. Turns out, there's an option in Gaia called "kernel routes" that you need to enable to make this work, and enabling it is pretty straightforward. If I had search SecureKnowledge earlier, I probably could have saved myself learning (and documenting) this lesson. It is documented in sk95869.
Now the Internet at home is working great once No delays in loading websites at all. At least ones caused by configuration errors on my part :)
Dynamic IP Gateway Security Policy
One of the challenges of using a Dynamic IP Gateway is that you don't know what the external IP is of your security gateway. Not knowing it could make it difficult to, say, make "port forwarding" rules or rules that relate to allowing traffic to the Security Gateway itself.
Turns out this is not an issue. When you check a gateway object as Dynamic IP as shown below, two Dynamic Objects come into play: LocalMachine (which always resolves to your gateway's external IP address) and LocalMachine_All_Interfaces which resolves to all of the IP addresses associated with your gateway. These dynamic objects are simply placeholder objects that get their actual definition updated on the local gateway. For these two objects in particular, this happens periodically without any action on the administrator's part.
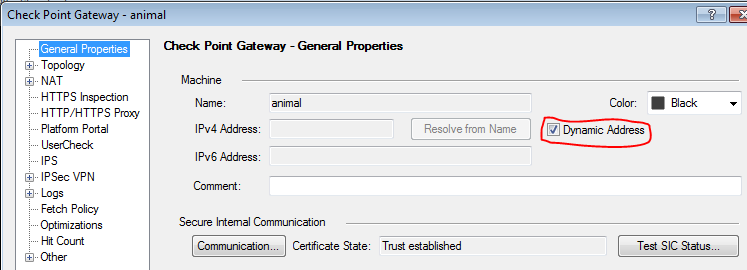
Dynamic Objects have a couple of important limitations. Rules using Dynamic Objects must be installed on a specific installation target, i.e. you cannot simply leave the Install On field for the rule the default Policy Targets. Not doing so will cause a policy compilation error. The second issue is that rules with Dynamic Objects disable SecureXL termplates at that rule. This isn't a huge deal as I'm coming nowhere near the capacity of my 2200, and most of my traffic is hitting rules with acceleration, but it is a consideration you must make when constructing your rulebase.
Another important limitation: Identity Awareness is not supported on Security Gateways that have a Dynamic IP. I do not believe this is an issue on the 600/1100 appliances, but it is for the 2200 and up.
Final Thoughts
It's been a while since I posted something technical on my own blog about using Check Point. My role is such that I'm not always involved in the technical side of things like I was back when I wasn't quite Internet famous :)
In any case, it may be something I'll do again in the future. I'm sure that pieces of this article will also show up in SecureKnowledge--the supported parts of the above at least.
And, of course, these are my own thoughts and experiences. Corrections and feedback are welcome.