Back when I started working with the Check Point product in 1996, things were much simpler. We still had plenty of IPv4 addresses, there weren’t a whole lot of users using the Internet, and applications were few and far between. To permit applications through a perimeter, it was generally considered best practice to open up the necessary TCP/UDP ports or use an application proxy.
For some applications, the act of opening up ports was complicated because the ports were determined dynamically. A good example of a classic protocol that does this is FTP. There were others, of course, but this was common back in the 1990s and is still used today. Check Point (and other vendors) had to have intelligence built into their product to account for FTP and a number of other protocols.
And then web-based applications became a thing. Now, if you’re allowing web traffic with no further classification, you might as well have an open firewall, because for all intents and purposes, it is. Even a single IP can host many different websites (some good, some not). And, of course, the content of a “good” website could also be “bad” at times. This created a clear need to control based not only on ports and IPs, but on other elements.
Enter Palo Alto Networks, who in 2007 released the first version of their product that is built around applications versus IP and ports. To be clear, this wasn’t a new concept as firewalls have been doing this in some capacity for years. However, Palo Alto’s approach resonated with customers, they gained market share, and other vendors started implementing similar technology.
The technology that Palo Alto Networks developed is called App-ID and they explain it as follows in their APP-ID Tech Brief:
App-ID uses multiple identification techniques to determine the exact identity of applications traversing your network – irrespective of port, protocol, evasive tactic, or encryption. Identifying the application is the very first task performed by App-ID, providing you with the knowledge and flexibility needed to safely enable applications and secure your organization.
Sounds magical. I can now build a security policy based on applications alone without regard to the ports they use? Or can I?
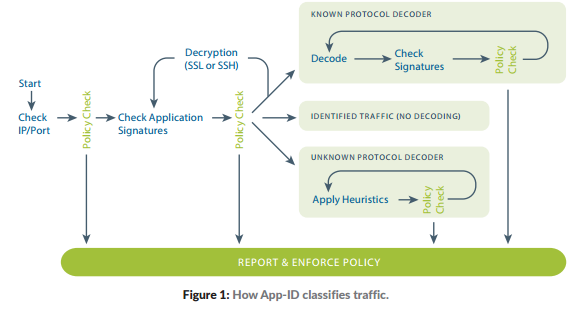
Even Palo Alto Network’s own documentation says the very first check is based on IP and Port, exactly the way every other vendor does it. You know why? Because that’s the only way to do it.
If I open a TCP connection to 192.0.2.1 port 80, the first packet sent is a TCP SYN. Here’s what I know from that:
- It’s likely a web-based connection. That said, anything can use port 80, so that’s only an assumption.
- It could be a connection to do a Google search, gmail, Google Maps, Google Drive, or any other Google property. Or Office 365 apps. Or something else.
- I might be able to do a reverse lookup on the IP to see where it’s going, but that adds latency and provides no guarantee the lookup will show you anything that will help identify the app or website. Or tell you if the content being served up is actually safe.
Bottom line: more information is needed. A few more packets must be let through on the connection before we know exactly what it is.
Let’s assume for a moment we take the position that we don’t care about ports at all, only applications, as I often hear Palo Alto Networks reps say. What can happen? First of all, you can do reconnaissance on anything beyond the firewall. If you do this rapidly, you’ll probably trigger the various protections in place to detect port scanning and similar activity, but it could easily be done in a “low and slow” manner that these detections probably won’t trigger.
Even Palo Alto Networks has a concept of ports that tie in with applications. This is configured on a per-rule/service basis, as shown below:
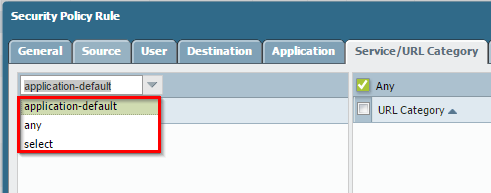
Per a post on their community, Application Default means:
Choosing this means that the selected applications are allowed or denied only on their default ports defined by Palo Alto Networks. This option is recommended for allow policies because it prevents applications from running on unusual ports and protocols, which if not intentional, can be a sign of undesired application behavior and usage.
Which is, of course, correct. Ports do matter as it filters out a lot of undesirable traffic. Palo Alto Networks simply masks this fact by allowing you to build only application-centric policies and not a separate policy for ports and applications the way Check Point currently does it.
Is an application-centric policy better? It certainly means less policies to have to configure and is one benefit to Palo Alto’s solution. Check Point will offer similar functionality in the R80.10 release, which, at this writing is currently available as a Public Early Availability release.
Whitelist versus Blacklist
This whole post spawned out of a discussion I started on LinkedIn when I posted this graphic, highlighting the number of applications supported by the different next generation firewall vendors:
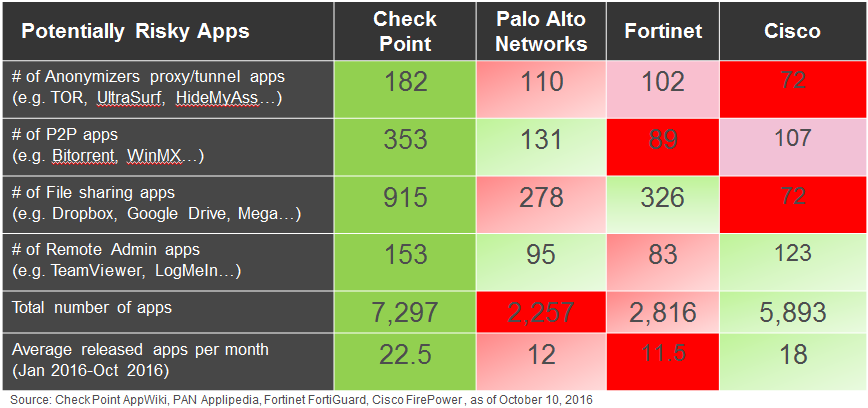
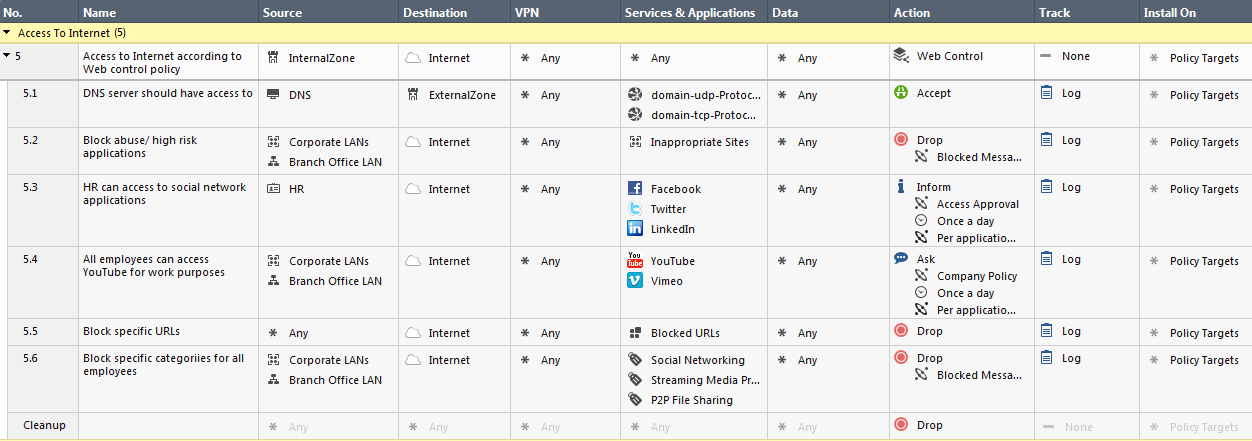
Various Palo Alto reps on the thread pointed out the number of applications supported didn’t matter as much because the way you should do it is to only allow specific applications and block the rest. Which, if you have a single policy for ports and applications, is a little easier to achieve. It is also possible to achieve in Check Point, but it does require some additional effort compared to Palo Alto.
Even with a whitelist approach where you permit only a small number of applications to pass, you have to be able to differentiate safe traffic from malicious traffic. As an example, specific anonymizers can appear to behave like innocuous web browsing. This is why Palo Alto Networks and others can also identify specific malicious applications to help differentiate.
It’s also why the number of applications a particular solution can identify matters greatly. As an example, I ran a Security Checkup at a Palo Alto Networks customer and saw the following applications:
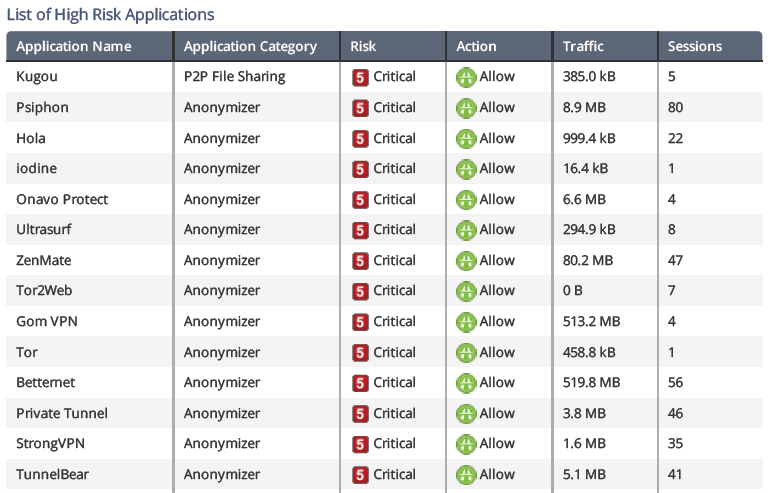
In this case, the Security Checkup appliance was positioned outside of a Palo Alto Networks gateway filtering traffic. The report from which this snapshot was taken ran in February 2016. You can see that Gom VPN and Betternet are clearly being allowed by the amount of traffic compared to some of the other ones, which are clearly being blocked due to the limited amount of traffic. I checked Applipedia and these anonymizers are still not supported (as of 11th December 2016, at least).
It’s also worth noting that a whitelist approach has a bit more administrative overhead and only works when the applications you want to allow are defined.
Clearly being able to detect more applications is better, even if you employ a whitelisting approach, which can have a bit more administrative overhead. Even then, it will only work when the applications you want to allow are defined. Thus again, more is better. And, as noted before, this whitelist strategy will be easier to implement in the Check Point R80.10 release.
Disclaimer: My employer, Check Point Software Technologies, is always trying to stay one step ahead of the threats as well as the competition. The views above, however, are my own.